
Liebe Frau Lengsfeld,
in dem am 29.09.2018 auf Ihrem Blog erschienenen Beitrag “Die erstaunlichen Unterschiede zwischen repräsentativ und roh bei Civey” beschreibt der Verfasser C. S. anhand zahlreicher Beispiele im Prinzip die selben Auffälligkeiten beim Vergleich der von Civey bei allen ihren Online-Umfragen angegebenen Rohdaten mit den daraus ermittelten Repräsentativdaten, wie ich sie in meiner am 18.09.2018 unter dem Titel “Diskrepanzen in Meinungsumfragen” ebenfalls auf Ihrem Blog veröffentlichten E-Mail an Sie auch schon beschrieben hatte. Am Ende fragt er sich (wie ich meine, völlig zu Recht):
- Was sagen die beiden unterschiedlichen Tabellen genau aus? Was genau also ist der Unterschied zwischen Repräsentativ und Rohdaten?
- Warum ist immer dann eine Differenz pro Regierungskurs hin zur “gewünschten Meinung“ festzustellen, je mehr ein Umfrageergebnis mal „etwas anders“ als politisch „gewünscht“ ausfällt?
Naturgemäß hatte ich mir damals im Prinzip die gleichen Fragen gestellt und habe daraufhin auch etwas genauer recherchiert, um herauszufinden, wie Civey aus den erhobenen Rohdaten die Repräsentativdaten ermittelt. Civey selbst hat dazu die folgenden beiden Dokumente veröffentlicht:
- Der statistische Fehler als Qualitätsindikator bei Civey (Civey Whitepaper).pdf
- Der Unterschied von Rohdaten und repräsentativen Ergebnissen
https://civey.com/blog/umfragen_methode_unterschied_rohdaten_repraesentative_ergebnisse/
Relevant für die oben gestellten Fragen ist zunächst einmal im Wesentlichen das zweite dieser Dokumente.
Es ist ein allseits bekanntes Problem bei allen Meinungsumfragen, dass das Kollektiv der Befragten niemals repräsentativ für alle Wähler bzw. Bürger eines Landes ist und dass die in einer Erhebung ermittelten Rohdaten daher unbedingt noch ‘nachbehandelt’ werden müssen, um zu einem objektiveren Ergebnis zu gelangen. So ist es z. B. sicherlich evident, dass unter den Teilnehmern einer Online-Umfrage die weniger Internet-affinen Kleinkinder und sehr alte Leute unterrepräsentiert sind, was entsprechende Korrekturen erfordert.
Wenn ein Umfrageinstitut Kenntnis hat über die Zugehörigkeit eines Befragten zu einer bestimmten Gruppe mit einem für diese Gruppe typischen Antwortverhalten bei der gestellten Frage, dann muss es die Antwort dieses Befragten mit einem Gewichtungsfaktor versehen, der sich aus dem Anteil dieser Gruppe an der Gesamtbevölkerung bzw. der Gesamtheit aller Wahlberechtigten ableitet. Ohne eine solche Korrektur würde eine überproportional hohe Beteiligung von Mitgliedern dieser Gruppe das Ergebnis in der Richtung ihres gruppentypischen Antwortverhaltens verfälschen. Unabdingbare Voraussetzung für die Durchführung derartiger Korrekturen ist demnach die oben erwähnte Kenntnis der Gruppenzugehörigkeit (Geschlecht , Alter, Bildungsgrad, Einkommen, Kaufverhalten, politische Präferenzen etc.) jedes Befragten, was sich insbesondere bei Online-Umfragen als durchaus problematisch erweisen kann. (Ich komme auf diesen Aspekt weiter unten noch zu sprechen.)
Nehmen wir uns als Beispiel die folgenden Ergebnissen einer Civey-Wahlumfrage zur anstehenden Landtagswahl in Bayer vor (Stand 24.09.2018):
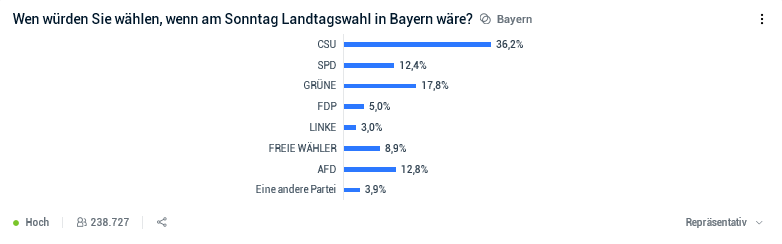
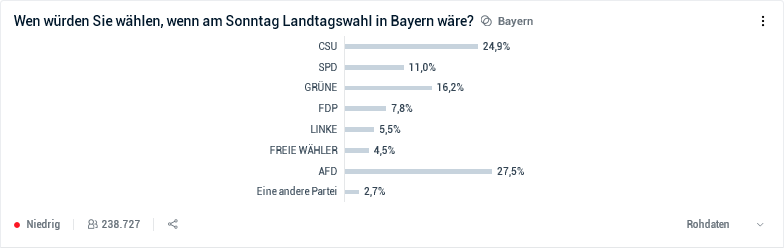
Hierbei fällt sofort auf, dass bei der Umrechnung der in den Rohdaten enthaltenen Prozentsätze der einzelnen Parteien in die als ‘Repräsentativ’ bezeichneten Prozentsätze die folgenden, untereinander sehr stark differierenden Umrechnungsfaktoren c = Repräsentativ/Rohdaten zur Anwendung kamen:
CSU: c = 36.2% / 24.9% = 1.454
SPD: c = 12.4% / 11.0% = 1.127
Grüne: c = 17.8% / 16.2% = 1.099
FDP: c = 5.0% / 7.8% = 0.641
Linke: c = 3.0% / 5.5% = 0.545
Freie Wähler: c = 8.9% / 4.5% = 1.978
AfD: c = 12.8% / 27.5% = 0.465
Beim Vergleich dieser Umrechnungsfaktoren c sieht man, dass die Stimmengewichte der CSU auf knapp das 1.5-Fache angehoben wurden und die Werte der SPD und der Grünen im Wesentlichen unverändert bleiben, weil Civey offensichtlich davon ausgeht, dass die Wählerschaft dieser Parteien zumindest halbwegs repräsentativ unter den Teilnehmern dieser Online-Umfrage vertreten war. Aus unerfindlichen Gründen unterstellt Civey den Unterstützern der Freien Wähler dagegen anscheinend eine regelrechte Umfrage-Phobie und hat daher deren Stimmengewichte nachträglich praktisch verdoppelt. Bei der Linken und noch ausgeprägter bei der AfD ist Civey jedoch offensichtlich der Meinung, dass deren Sympathisanten ausgesprochen Umfrage-süchtig sind und dass deren Rohdaten daher in etwa halbiert werden müssen, im Fall der AfD sogar mehr als halbiert.
Aber woher bezieht Civey die für diese Korrekturen zwingend erforderliche Kenntnis der politischen Präferenz jedes einzelnen Teilnehmers an dieser Online-Umfrage? Civey gibt in der o. g. Firmenschrift “Der Unterschied von Rohdaten und repräsentativen Ergebnissen” an, dass sie zur Auswertung der Klickzahlen nur die Antworten von bei Civey zuvor registrierten Teilnehmern heranziehen. Hierbei fragt Civey ganz bestimmte Merkmale dieser Personen ab, “wie z. B. Alter, Geschlecht, Region, Bildungsstand …” und eben auch “politische Orientierung“. Wer sich dieser Registrierung unterzieht, muss sich natürlich klarmachen, was er damit über sich preisgibt und dass er danach keine Kontrolle mehr darüber hat, wer mit diesen Daten dann später was anstellt. Mit anderen Worten, er macht sich zum gläsernen Menschen. Aus diesem Civey-Dokument geht auch hervor, dass Civey das Abstimmungsverhalten eines jeden Teilnehmers persönlich (wahrscheinlich unter Einsatz von cookies) verfolgt und dauerhaft speichert (Zitat): “Aus den Rohdaten kann man ablesen, wie die Menschen in der Vergangenheit in absoluten Zahlen an unserer Umfrage abgestimmt haben …“. Wie derartige Schnüffelpraktiken mit der DSGVO und anderen Gesetzen vereinbar sein sollen, ist mir juristischem Laien nicht wirklich klar. Da sollte vielleicht mal die Bundesdatenschutzbeauftragte etwas genauer nachhaken (sofern ihr die Bundesregierung das überhaupt noch gestattet).
Diese Korrektur der Rohdaten ist ganz unzweifelhaft eine extrem schwierige, wenn nicht gar fast unlösbare Aufgabe. Das geht auch aus dem o. g. ersten Dokument “Der statistische Fehler als Qualitätsindikator bei Civey (Civey Whitepaper).pdf” hervor. Civey selbst gibt in diesem Dokument auch mehr oder weniger unumwunden zu, dass diese (Zitat) “Schätzungen” von mir etwas salopp ausgedrückt z. T. eine ziemlich windige Kaffeesatzleserei sind:
Die Entscheidung, den statistischen Fehler mit Bayesianischen Methoden zu berechnen, akzeptiert ganz explizit ein subjektives Element in der Schätzung der Umfrageergebnisse. Dieser Einfluss schlägt sich in der Modellierung von demographischen Diskrepanzen und des Einflusses von politischen und Verhaltensvariablen nieder. Ähnliche Methoden werden allerdings in den allermeisten Umfragen angewandt, sodass wir es für konsequent halten, offen mit diesem Umstand umzugehen und hoffen, damit einen Beitrag zur Debatte über die Zukunft der Meinungsforschung zu leisten. In bestem Bayesianischem Sinne entwickeln wir unsere Modelle natürlich dauerhaft weiter und beziehen neue Informationen ein, um die bestmögliche Genauigkeit in unseren Umfragen zu erreichen.
Was mich an diesem Text am meisten beunruhigt, ist der darin verwendete Begriff “politischen und Verhaltensvariablen“. Geht die Schnüffelei inzwischen schon so weit, dass bei einer solchen Online-Umfrage mein Rechner heimlich durchsucht wird, um auf diesem Weg meine politische Einstellung abzufragen?
Eine solche auf z. T. mehr oder weniger willkürlich geschätzten Korrekturfaktoren basierende Vorgehensweise, der man m. E. daher nur bedingt das Attribut “wissenschaftlich” zubilligen kann, öffnet natürlich der “Anpassung” der “repräsentativen” Ergebnisse an die Wünsche bzw. Vorgaben des jeweiligen Auftraggebers einer solchen Umfrage Tür und Tor.
Zurück zu besagter Civey-Umfrage zur bayerischen Landtagswahl 2018: Dass angesichts derartiger (für die Umfrage zwar nützlichen, aber rechtlich höchst bedenklichen) Praktiken unter den Teilnehmern dieser Umfrage, die z. B. aus ihrer “politischen Orientierung” keinen Hehl machen, ausgerechnet (immerhin um den beachtlichen Faktor 1/c = 2.148) überproportional viele potenzielle AfD-Wähler sein sollen, das scheint mir jedoch nach allem, was man über die Zurückhaltung bei dem öffentlichen Bekenntnis zu dieser Partei weiß, eine gelinde gesagt ‘kühne’ These zu sein. So gesehen teile ich die von Ihrem Gastautor C. S. am Ende seines Beitrags geäußerte Schlussfolgerung “dass nicht sein kann, was nicht sein darf” voll und ganz.
Wie die übrigen Umfrage-Institute genau zu ihren Umrechnungsfaktoren kommen, wird, wenn überhaupt, von diesen meist nur recht nebulös beschrieben – wohl auch, weil das letztlich den Kern ihrer Betriebsgeheimnisse darstellt. Hierfür sollte man allerdings auch ein gewisses Verständnis aufbringen, denn diese Institute hängen ja wirtschaftlich davon ab, aufgrund möglichst zutreffender Ergebnisse von ihren Auftraggebern auch in Zukunft wieder Folgeaufträge zu erhalten.
Und damit sind wir bei des Pudels Kern: dem Geld. Da die Civey-Online-Umfragen großteils auf den Internetseiten unserer Presse-Medien zu finden sind, ist sicher die Vermutung naheliegend, dass diese Medien meistens auch die Auftraggeber sind. Nachdem unsere Presse-Medien (anders als in den ersten 50 Jahren der Bundesrepublik) inzwischen in großen Teilen absolut politisch korrekt und alles andere als regierungskritisch eingestellt sind, muss es in diesem Zusammenhang auch erlaubt sein, den Verdacht “Wes Brot ich fress, des Lied ich sing” als einen möglichen Erklärungsansatz für die “erstaunlichen Unterschiede zwischen repräsentativ und roh” zumindest näher in Betracht zu ziehen.
Ich hoffe, die Fragen Ihres Gastautors C. S. mit meinem “Ich weiß es nicht genau, aber ich vermute etwas” ausreichend beantwortet zu haben.
Viele Grüße,
M. D.
Unabhängiger Journalismus ist zeitaufwendig
Dieser Blog ist ein Ein-Frau-Unternehmen. Wenn Sie meine Arbeit unterstützen wollen, nutzen Sie dazu meine Kontoverbindung oder PayPal:
Vera Lengsfeld
IBAN: DE55 3101 0833 3114 0722 20
Bic: SCFBDE33XXX
oder per PayPal:
